table - Working with tabular data¶
This module defines the table class that provides convenient functionality to work with tabular data. It features functions to calculate statistical moments, e.g. mean, standard deviations as well as functionality to plot the data using matplotlib.
Basic Usage¶
Populate table with data and plot the data:
from ost.table import *
# create table with two columns, x and y both of float type
tab = Table(['x', 'y'], 'ff')
for x in range(1000):
tab.AddRow([x, x**2])
# create a plot
plt = tab.Plot('x', 'y')
# save resulting plot to png file
plt.savefig('x-vs-y.png')
Iterating over table items:
# load table from file
tab = Table.Load(...)
# get column index for col 'foo'
idx = tab.GetColIndex('foo')
# iterate over all rows
for row in tab.rows:
# print complete row
print row
# print value for column 'foo'
print row[idx]
# iterate over all rows of selected columns
for foo, bar in tab.Zip('foo','bar'):
print foo, bar
Doing element wise mathematical operations on entire colums:
# create table with two columns, foo and bar both of int type
# and fill with values
tab = Table(['foo', 'bar'], 'ii', foo=[1,2,3,4], bar=[1,4,9,16])
# add new column by doing an element wise
# addition of column foo and column bar
tab.AddCol('qux', 'f', tab['foo']+tab['bar'])
print tab
Select part of the table based on a query:
# create table with two columns, foo and bar both of int type
# and fill with values
tab = Table(['foo', 'bar'], 'ii', foo=[1,2,3,4], bar=[1,4,9,16])
# select all rows where foo>=2 and bar<10
subtab = tab.Select('foo>=2 and bar<10')
print subtab
# select all rows where foo>3 or bar=1
subtab = tab.Select('foo>3 or bar=1')
print subtab
Functions You Might be Interested In¶
| Adding/Removing/Reordering data | |
AddRow() |
add a row to the table |
AddCol() |
add a column to the table |
RemoveCol() |
remove a column from the table |
RenameCol() |
rename a column |
Extend() |
append a table to the end of another table |
Merge() |
merge two tables together |
Sort() |
sort table by column |
Filter() |
filter table by values |
Select() |
select subtable based on query |
Zip() |
extract multiple columns at once |
SearchColNames() |
search for matching column names |
| Input/Output | |
Save() |
save a table to a file |
Load() |
load a table from a file |
ToString() |
convert a table to a string for printing |
| Simple Math | |
Min() |
compute the minimum of a column |
Max() |
compute the maximum of a column |
Sum() |
compute the sum of a column |
Mean() |
compute the mean of a column |
RowMean() |
compute the mean for each row |
Median() |
compute the median of a column |
StdDev() |
compute the standard deviation of a column |
Count() |
compute the number of items in a column |
| More Sophisticated Math | |
Correl() |
compute Pearson’s correlation coefficient |
SpearmanCorrel() |
compute Spearman’s rank correlation coefficient |
ComputeMCC() |
compute Matthew’s correlation coefficient |
ComputeROC() |
compute receiver operating characteristics (ROC) |
ComputeEnrichment() |
compute enrichment |
GetOptimalPrefactors() |
compute optimal coefficients for linear combination of columns |
| Plot | |
Plot() |
Plot data in 1, 2 or 3 dimensions |
PlotHistogram() |
Plot data as histogram |
PlotROC() |
Plot receiver operating characteristics (ROC) |
PlotEnrichment() |
Plot enrichment |
PlotHexbin() |
Hexagonal density plot |
PlotBar() |
Bar plot |
The Table class¶
-
class
Table(col_names=[], col_types=None, **kwargs)¶ The table class provides convenient access to data in tabular form. An empty table can be easily constructed as follows
tab = Table()
If you want to add columns directly when creating the table, column names and column types can be specified as follows
tab = Table(['nameX','nameY','nameZ'], 'sfb')
this will create three columns called nameX, nameY and nameZ of type string, float and bool, respectively. There will be no data in the table and thus, the table will not contain any rows.
The following column types are supported:
name abbrev string s float f int i bool b If you want to add data to the table in addition, use the following:
tab=Table(['nameX','nameY','nameZ'], 'sfb', nameX = ['a','b','c'], nameY = [0.1, 1.2, 3.414], nameZ = [True, False, False])
if values for one column is left out, they will be filled with NA, but if values are specified, all values must be specified (i.e. same number of values per column)
-
AddCol(col_name, col_type, data=None)¶ Add a column to the right of the table.
Parameters: - col_name (
str) – name of new column - col_type (
str) – type of new column (long versions: int, float, bool, string or short versions: i, f, b, s) - data (scalar or iterable) – data to add to new column
Example:
tab = Table(['x'], 'f', x=range(5)) tab.AddCol('even', 'bool', itertools.cycle([True, False])) print tab ''' will produce the table ==== ==== x even ==== ==== 0 True 1 False 2 True 3 False 4 True ==== ==== '''
If data is a constant instead of an iterable object, it’s value will be written into each row:
tab = Table(['x'], 'f', x=range(5)) tab.AddCol('num', 'i', 1) print tab ''' will produce the table ==== ==== x num ==== ==== 0 1 1 1 2 1 3 1 4 1 ==== ==== '''
As a special case, if there are no previous rows, and data is not None, rows are added for every item in data.
- col_name (
-
AddRow(data, overwrite=None)¶ Add a row to the table.
data may either be a dictionary or a list-like object:
- If data is a dictionary, the keys in the dictionary must match the
column names. Columns not found in the dict will be initialized to None.
If the dict contains list-like objects, multiple rows will be added, if
the number of items in all list-like objects is the same, otherwise a
ValueErroris raised. - If data is a list-like object, the row is initialized from the values
in data. The number of items in data must match the number of
columns in the table. A
ValuerErroris raised otherwise. The values are added in the order specified in the list, thus, the order of the data must match the columns.
If overwrite is not None and set to an existing column name, the specified column in the table is searched for the first occurrence of a value matching the value of the column with the same name in the dictionary. If a matching value is found, the row is overwritten with the dictionary. If no matching row is found, a new row is appended to the table.
Parameters: - data (
dictor list-like object) – data to add - overwrite (
str) – column name to overwrite existing row if value in column overwrite matches
Raises: ValueErrorif list-like object is used and number of items does not match number of columns in table.Raises: ValueErrorif dict is used and multiple rows are added but the number of data items is different for different columns.Example: add multiple data rows to a subset of columns using a dictionary
# create table with three float columns tab = Table(['x','y','z'], 'fff') # add rows from dict data = {'x': [1.2, 1.6], 'z': [1.6, 5.3]} tab.AddRow(data) print tab ''' will produce the table ==== ==== ==== x y z ==== ==== ==== 1.20 NA 1.60 1.60 NA 5.30 ==== ==== ==== ''' # overwrite the row with x=1.2 and add row with x=1.9 data = {'x': [1.2, 1.9], 'z': [7.9, 3.5]} tab.AddRow(data, overwrite='x') print tab ''' will produce the table ==== ==== ==== x y z ==== ==== ==== 1.20 NA 7.90 1.60 NA 5.30 1.90 NA 3.50 ==== ==== ==== '''
- If data is a dictionary, the keys in the dictionary must match the
column names. Columns not found in the dict will be initialized to None.
If the dict contains list-like objects, multiple rows will be added, if
the number of items in all list-like objects is the same, otherwise a
-
ComputeEnrichment(score_col, class_col, score_dir='-', class_dir='-', class_cutoff=2.0)¶ Computes the enrichment of column score_col classified according to class_col.
For this it is necessary, that the datapoints are classified into positive and negative points. This can be done in two ways:
- by using one ‘bool’ type column (class_col) which contains True for positives and False for negatives
- by specifying a classification column (class_col), a cutoff value
(class_cutoff) and the classification columns direction (class_dir).
This will generate the classification on the fly
- if
class_dir=='-': values in the classification column that are less than or equal to class_cutoff will be counted as positives - if
class_dir=='+': values in the classification column that are larger than or equal to class_cutoff will be counted as positives
- if
During the calculation, the table will be sorted according to score_dir, where a ‘-‘ values means smallest values first and therefore, the smaller the value, the better.
Warning: If either the value of class_col or score_col is None, the data in this row is ignored.
-
ComputeEnrichmentAUC(score_col, class_col, score_dir='-', class_dir='-', class_cutoff=2.0)¶ Computes the area under the curve of the enrichment using the trapezoidal rule.
For more information about parameters of the enrichment, see
ComputeEnrichment().Warning: The function depends on numpy
-
ComputeLogROCAUC(score_col, class_col, score_dir='-', class_dir='-', class_cutoff=2.0)¶ Computes the area under the curve of the log receiver operating characteristics (logROC) where the x-axis is semilogarithmic using the trapezoidal rule.
The logROC is computed with a lambda of 0.001 according to Rapid Context-Dependent Ligand Desolvation in Molecular Docking Mysinger M. and Shoichet B., Journal of Chemical Information and Modeling 2010 50 (9), 1561-1573
For more information about parameters of the ROC, see
ComputeROC().Warning: The function depends on numpy
-
ComputeMCC(score_col, class_col, score_dir='-', class_dir='-', score_cutoff=2.0, class_cutoff=2.0)¶ Compute Matthews correlation coefficient (MCC) for one column (score_col) with the points classified into true positives, false positives, true negatives and false negatives according to a specified classification column (class_col).
The datapoints in score_col and class_col are classified into positive and negative points. This can be done in two ways:
- by using ‘bool’ columns which contains True for positives and False for negatives
- by using ‘float’ or ‘int’ columns and specifying a cutoff value and the
columns direction. This will generate the classification on the fly
- if
class_dir/score_dir=='-': values in the classification column that are less than or equal to class_cutoff/score_cutoff will be counted as positives - if
class_dir/score_dir=='+': values in the classification column that are larger than or equal to class_cutoff/score_cutoff will be counted as positives
- if
The two possibilities can be used together, i.e. ‘bool’ type for one column and ‘float’/’int’ type and cutoff/direction for the other column.
-
ComputeROC(score_col, class_col, score_dir='-', class_dir='-', class_cutoff=2.0)¶ Computes the receiver operating characteristics (ROC) of column score_col classified according to class_col.
For this it is necessary, that the datapoints are classified into positive and negative points. This can be done in two ways:
- by using one ‘bool’ column (class_col) which contains True for positives and False for negatives
- by using a non-bool column (class_col), a cutoff value (class_cutoff)
and the classification columns direction (class_dir). This will generate
the classification on the fly
- if
class_dir=='-': values in the classification column that are less than or equal to class_cutoff will be counted as positives - if
class_dir=='+': values in the classification column that are larger than or equal to class_cutoff will be counted as positives
- if
During the calculation, the table will be sorted according to score_dir, where a ‘-‘ values means smallest values first and therefore, the smaller the value, the better.
If class_col does not contain any positives (i.e. value is True (if column is of type bool) or evaluated to True (if column is of type int or float (depending on class_dir and class_cutoff))) the ROC is not defined and the function will return None.
Warning: If either the value of class_col or score_col is None, the data in this row is ignored.
-
ComputeROCAUC(score_col, class_col, score_dir='-', class_dir='-', class_cutoff=2.0)¶ Computes the area under the curve of the receiver operating characteristics using the trapezoidal rule.
For more information about parameters of the ROC, see
ComputeROC().Warning: The function depends on numpy
-
Correl(col1, col2)¶ Calculate the Pearson correlation coefficient between col1 and col2, only taking rows into account where both of the values are not equal to None. If there are not enough data points to calculate a correlation coefficient, None is returned.
Parameters: - col1 (
str) – column name for first column - col2 (
str) – column name for second column
- col1 (
-
Count(col, ignore_nan=True)¶ Count the number of cells in column that are not equal to ‘’None’‘.
Parameters: - col (
str) – column name - ignore_nan (
bool) – ignore all None values
- col (
-
Extend(tab, overwrite=None)¶ Append each row of tab to the current table. The data is appended based on the column names, thus the order of the table columns is not relevant, only the header names.
If there is a column in tab that is not present in the current table, it is added to the current table and filled with None for all the rows present in the current table.
If the type of any column in tab is not the same as in the current table a TypeError is raised.
If overwrite is not None and set to an existing column name, the specified column in the table is searched for the first occurrence of a value matching the value of the column with the same name in the dictionary. If a matching value is found, the row is overwritten with the dictionary. If no matching row is found, a new row is appended to the table.
-
Filter(*args, **kwargs)¶ Returns a filtered table only containing rows matching all the predicates in kwargs and args For example,
tab.Filter(town='Basel')
will return all the rows where the value of the column “town” is equal to “Basel”. Several predicates may be combined, i.e.
tab.Filter(town='Basel', male=True)
will return the rows with “town” equal to “Basel” and “male” equal to true. args are unary callables returning true if the row should be included in the result and false if not.
-
GaussianSmooth(col, std=1.0, na_value=0.0, padding='reflect', c=0.0)¶ In place Gaussian smooth of a column in the table with a given standard deviation. All nan are set to nan_value before smoothing.
Parameters: - col (
str) – column name - std (scalar) – standard deviation for gaussian kernel
- na_value (scalar) – all na (None) values of the speciefied column are set to na_value before smoothing
- padding (
str) – allows to handle padding behaviour see scipy ndimage.gaussian_filter1d documentation for more information. standard is reflect - c (scalar) – constant value used for padding if padding mode is constant
Warning: The function depends on scipy
- col (
-
GetColIndex(col)¶ Returns the column index for the column with the given name.
Raises: ValueError if no column with the name is found.
-
GetColNames()¶ Returns a list containing all column names.
-
GetName()¶ Get name of table
-
GetNumpyMatrix(*args)¶ Returns a numpy matrix containing the selected columns from the table as columns in the matrix.
Only columns of type int or float are supported. NA values in the table will be converted to None values.
Parameters: *args – column names to include in numpy matrix Warning: The function depends on numpy
-
GetOptimalPrefactors(ref_col, *args, **kwargs)¶ This returns the optimal prefactor values (i.e. a, b, c, ...) for the following equation
(1)
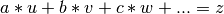
where u, v, w and z are vectors. In matrix notation
(2)
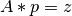
where A contains the data from the table (u,v,w,...), p are the prefactors to optimize (a,b,c,...) and z is the vector containing the result of equation (1).
The parameter ref_col equals to z in both equations, and *args are columns u, v and w (or A in (2)). All columns must be specified by their names.
Example:
tab.GetOptimalPrefactors('colC', 'colA', 'colB')
The function returns a list of containing the prefactors a, b, c, ... in the correct order (i.e. same as columns were specified in *args).
Weighting: If the kwarg weights=”columX” is specified, the equations are weighted by the values in that column. Each row is multiplied by the weight in that row, which leads to (3):
(3)
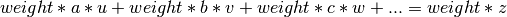
Weights must be float or int and can have any value. A value of 0 ignores this equation, a value of 1 means the same as no weight. If all weights are the same for each row, the same result will be obtained as with no weights.
Example:
tab.GetOptimalPrefactors('colC', 'colA', 'colB', weights='colD')
-
GetUnique(col, ignore_nan=True)¶ Extract a list of all unique values from one column.
Parameters: - col (
str) – column name - ignore_nan (
bool) – ignore all None values
- col (
-
HasCol(col)¶ Checks if the column with a given name is present in the table.
-
IsEmpty(col_name=None, ignore_nan=True)¶ Checks if a table is empty.
If no column name is specified, the whole table is checked for being empty, whereas if a column name is specified, only this column is checked.
By default, all NAN (or None) values are ignored, and thus, a table containing only NAN values is considered as empty. By specifying the option ignore_nan=False, NAN values are counted as ‘normal’ values.
-
static
Load(stream_or_filename, format='auto', sep=', ')¶ Load table from stream or file with given name.
By default, the file format is set to auto, which tries to guess the file format from the file extension. The following file extensions are recognized:
extension recognized format .csv comma separated values .pickle pickled byte stream <all others> ost-specific format Thus, format must be specified for reading file with different filename extensions.
The following file formats are understood:
ost
This is an ost-specific, but still human readable file format. The file (stream) must start with header line of the form
col_name1[type1] <col_name2[type2]>...
The types given in brackets must be one of the data types the
Tableclass understands. Each following line in the file then must contains exactly the same number of data items as listed in the header. The data items are automatically converted to the column format. Lines starting with a ‘#’ and empty lines are ignored.pickle
Deserializes the table from a pickled byte stream.
csv
Reads the table from comma separated values stream. Since there is no explicit type information in the csv file, the column types are guessed, using the following simple rules:
- if all values are either NA/NULL/NONE the type is set to string.
- if all non-null values are convertible to float/int the type is set to float/int.
- if all non-null values are true/false/yes/no, the value is set to bool.
- for all other cases, the column type is set to string.
Returns: A new Tableinstance
-
Max(col)¶ Returns the maximum value in col. If several rows have the highest value, only the first one is returned. ‘’None’’ values are ignored.
Parameters: col ( str) – column name
-
MaxIdx(col)¶ Returns the row index of the cell with the maximal value in col. If several rows have the highest value, only the first one is returned. ‘’None’’ values are ignored.
Parameters: col ( str) – column name
-
MaxRow(col)¶ Returns the row containing the cell with the maximal value in col. If several rows have the highest value, only the first one is returned. ‘’None’’ values are ignored.
Parameters: col ( str) – column nameReturns: row with maximal col value or None if the table is empty
-
Mean(col)¶ Returns the mean of the given column. Cells with ‘’None’’ are ignored. Returns None, if the column doesn’t contain any elements. Col must be of numeric (‘float’, ‘int’) or boolean column type.
If column type is bool, the function returns the ratio of number of ‘Trues’ by total number of elements.
Parameters: col ( str) – column nameRaises: TypeErrorif column type isstring
-
Median(col)¶ Returns the median of the given column. Cells with ‘’None’’ are ignored. Returns ‘’None’‘, if the column doesn’t contain any elements. Col must be of numeric column type (‘float’, ‘int’) or boolean column type.
Parameters: col ( str) – column nameRaises: TypeErrorif column type isstring
-
Min(col)¶ Returns the minimal value in col. If several rows have the lowest value, only the first one is returned. ‘’None’’ values are ignored.
Parameters: col ( str) – column name
-
MinIdx(col)¶ Returns the row index of the cell with the minimal value in col. If several rows have the lowest value, only the first one is returned. ‘’None’’ values are ignored.
Parameters: col ( str) – column name
-
MinRow(col)¶ Returns the row containing the cell with the minimal value in col. If several rows have the lowest value, only the first one is returned. ‘’None’’ values are ignored.
Parameters: col ( str) – column nameReturns: row with minimal col value or None if the table is empty
-
PairedTTest(col_a, col_b)¶ Two-sided test for the null-hypothesis that two related samples have the same average (expected values).
Parameters: - col_a (
str) – First column - col_b (
str) – Second column
Returns: P-value between 0 and 1 that the two columns have the same average. The smaller the value, the less related the two columns are.
- col_a (
-
Percentiles(col, nths)¶ Returns the percentiles of column col given in nths.
The percentiles are calculated as
values[min(len(values), int(round(len(values)*nth/100+0.5)-1))]
where values are the sorted values of col not equal to ‘’None’‘
Parameters: - col (
str) – column name - nths (
listof numbers) – list of percentiles to be calculated. Each percentile is a number between 0 and 100.
Raises: TypeErrorif column type isstringReturns: List of percentiles in the same order as given in nths
- col (
-
Plot(x, y=None, z=None, style='.', x_title=None, y_title=None, z_title=None, x_range=None, y_range=None, z_range=None, color=None, plot_if=None, legend=None, num_z_levels=10, z_contour=True, z_interpol='nn', diag_line=False, labels=None, max_num_labels=None, title=None, clear=True, save=False, **kwargs)¶ Function to plot values from your table in 1, 2 or 3 dimensions using Matplotlib
Parameters: - x (
str) – column name for first dimension - y (
str) – column name for second dimension - z (
str) – column name for third dimension - style (
str) – symbol style (e.g. ., -, x, o, +, *). For a complete list check (matplotlib docu). - x_title (
str) – title for first dimension, if not specified it is automatically derived from column name - y_title (
str) – title for second dimension, if not specified it is automatically derived from column name - z_title (
str) – title for third dimension, if not specified it is automatically derived from column name - x_range (
listof length two) – start and end value for first dimension (e.g. [start_x, end_x]) - y_range (
listof length two) – start and end value for second dimension (e.g. [start_y, end_y]) - z_range (
listof length two) – start and end value for third dimension (e.g. [start_z, end_z]) - color (
str) – color for data (e.g. b, g, r). For a complete list check (matplotlib docu). - plot_if (callable) – callable which returnes True if row should be plotted. Is
invoked like
plot_if(self, row) - legend (
str) – legend label for data series - num_z_levels (
int) – number of levels for third dimension - diag_line (
bool) – draw diagonal line - labels (
str) – column name containing labels to put on x-axis for one dimensional plot - max_num_labels (
int) – limit maximum number of labels - title (
str) – plot title, if not specified it is automatically derived from plotted column names - clear (
bool) – clear old data from plot - save (
str) – filename for saving plot - z_contour (
bool) – draw contour lines - z_interpol (
str) – interpolation method for 3-dimensional plot (one of ‘nn’, ‘linear’) - **kwargs – additional arguments passed to matplotlib
Returns: the
matplotlib.pyplotmoduleExamples: simple plotting functions
tab = Table(['a','b','c','d'],'iffi', a=range(5,0,-1), b=[x/2.0 for x in range(1,6)], c=[math.cos(x) for x in range(0,5)], d=range(3,8)) # one dimensional plot of column 'd' vs. index plt = tab.Plot('d') plt.show() # two dimensional plot of 'a' vs. 'c' plt = tab.Plot('a', y='c', style='o-') plt.show() # three dimensional plot of 'a' vs. 'c' with values 'b' plt = tab.Plot('a', y='c', z='b') # manually save plot to file plt.savefig("plot.png")
- x (
-
PlotBar(cols=None, rows=None, xlabels=None, set_xlabels=True, xlabels_rotation='horizontal', y_title=None, title=None, colors=None, width=0.8, bottom=0, legend=False, legend_names=None, show=False, save=False)¶ Create a barplot of the data in cols. Every column will be represented at one position. If there are several rows, each column will be grouped together.
Parameters: - cols (
list) – List of column names. Every column will be represented as a single bar. If cols is None, every column of the table gets plotted. - rows (
list) – List of row indices. Values from given rows will be plotted in parallel at one column position. If set to None, all rows of the table will be plotted. Note, that the maximum number of rows is 7. - xlabels (
list) – Label for every col on x-axis. If set to None, the column names are used. The xlabel plotting can be supressed by the parameter set_xlabel. - set_xlabels (
bool) – Controls whether xlabels are plotted or not. - x_labels_rotation – Can either be ‘horizontal’, ‘vertical’ or an integer, that describes the rotation in degrees.
- y_title (
str) – Y-axis description - colors (
list) – Colors of the different bars in each group. Must be a list of valid colors in matplotlib. Length of color and rows must be consistent. - width (
float) – The available space for the groups on the x-axis is divided by the exact number of groups. The parameters width is the fraction of what is actually used. If it would be 1.0 the bars of the different groups would touch each other. Value must be between [0;1] - bottom (
float) – Bottom - legend (
bool) – Legend for color explanation, the corresponding row respectively. If set to True, legend_names must be provided. - legend_names – List of names, that describe the differently colored bars. Length must be consistent with number of rows.
- show – If set to True, the plot is directly displayed.
- save (
str) – If set, a png image with name save in the current working directory will be saved.
Title: Title of the plot. No title appears if set to None
- cols (
-
PlotEnrichment(score_col, class_col, score_dir='-', class_dir='-', class_cutoff=2.0, style='-', title=None, x_title=None, y_title=None, clear=True, save=None)¶ Plot an enrichment curve using matplotlib of column score_col classified according to class_col.
For more information about parameters of the enrichment, see
ComputeEnrichment(), and for plotting seePlot().Warning: The function depends on matplotlib
-
PlotHexbin(x, y, title=None, x_title=None, y_title=None, x_range=None, y_range=None, binning='log', colormap='jet', show_scalebar=False, scalebar_label=None, clear=True, save=False, show=False)¶ Create a heatplot of the data in col x vs the data in col y using matplotlib
Parameters: - x (
str) – column name with x data - y (
str) – column name with y data - title (
str) – title of the plot, will be generated automatically if set to None - x_title – label of x-axis, will be generated automatically if set to None
- y_title – label of y-axis, will be generated automatically if set to None
- x_range (
listof length two) – start and end value for first dimension (e.g. [start_x, end_x]) - y_range (
listof length two) – start and end value for second dimension (e.g. [start_y, end_y]) - binning – type of binning. If set to None, the value of a hexbin will correspond to the number of datapoints falling into it. If set to ‘log’, the value will be the log with base 10 of the above value (log(i+1)). If an integer is provided, the number of a hexbin is equal the number of datapoints falling into it divided by the integer. If a list of values is provided, these values will be the lower bounds of the bins.
- colormap – colormap, that will be used. Value can be every colormap defined in matplotlib or an own defined colormap. You can either pass a string with the name of the matplotlib colormap or a colormap object.
- show_scalebar (
bool) – If set to True, a scalebar according to the chosen colormap is shown - scalebar_label (
str) – Label of the scalebar - clear (
bool) – clear old data from plot - save (
str) – filename for saving plot - show (
bool) – directly show plot
- x (
-
PlotHistogram(col, x_range=None, num_bins=10, normed=False, histtype='stepfilled', align='mid', x_title=None, y_title=None, title=None, clear=True, save=False, color=None, y_range=None)¶ Create a histogram of the data in col for the range x_range, split into num_bins bins and plot it using Matplotlib.
Parameters: - col (
str) – column name with data - x_range (
listof length two) – start and end value for first dimension (e.g. [start_x, end_x]) - y_range (
listof length two) – start and end value for second dimension (e.g. [start_y, end_y]) - num_bins (
int) – number of bins in range - color (
str) – Color to be used for the histogram. If not set, color will be determined by matplotlib - normed (
bool) – normalize histogram - histtype (
str) – type of histogram (i.e. bar, barstacked, step, stepfilled). See (matplotlib docu). - align (
str) – style of histogram (left, mid, right). See (matplotlib docu). - x_title (
str) – title for first dimension, if not specified it is automatically derived from column name - y_title (
str) – title for second dimension, if not specified it is automatically derived from column name - title (
str) – plot title, if not specified it is automatically derived from plotted column names - clear (
bool) – clear old data from plot - save (
str) – filename for saving plot
Examples: simple plotting functions
tab = Table(['a'],'f', a=[math.cos(x*0.01) for x in range(100)]) # one dimensional plot of column 'd' vs. index plt = tab.PlotHistogram('a') plt.show()
- col (
-
PlotLogROC(score_col, class_col, score_dir='-', class_dir='-', class_cutoff=2.0, style='-', title=None, x_title=None, y_title=None, clear=True, save=None)¶ Plot an logROC curve where the x-axis is semilogarithmic using matplotlib
For more information about parameters of the ROC, see
ComputeROC(), and for plotting seePlot().Warning: The function depends on matplotlib
-
PlotROC(score_col, class_col, score_dir='-', class_dir='-', class_cutoff=2.0, style='-', title=None, x_title=None, y_title=None, clear=True, save=None)¶ Plot an ROC curve using matplotlib.
For more information about parameters of the ROC, see
ComputeROC(), and for plotting seePlot().Warning: The function depends on matplotlib
-
RemoveCol(col)¶ Remove column with the given name from the table.
Parameters: col ( str) – name of column to remove
-
RenameCol(old_name, new_name)¶ Rename column old_name to new_name.
Parameters: - old_name – Name of the old column
- new_name – Name of the new column
Raises: ValueErrorwhen old_name is not a valid column
-
RowMean(mean_col_name, cols)¶ Adds a new column of type ‘float’ with a specified name (mean_col_name), containing the mean of all specified columns for each row.
Cols are specified by their names and must be of numeric column type (‘float’, ‘int’) or boolean column type. Cells with None are ignored. Adds ‘’None’’ if the row doesn’t contain any values.
Parameters: - mean_col_name (
str) – name of new column containing mean values - cols (
strorlistof strings) – name or list of names of columns to include in computation of mean
Raises: TypeErrorif column type of columns in col isstring== Example ==
Staring with the following table:
x y u 1 10 100 2 15 None 3 20 400 the code here adds a column with the name ‘mean’ to yield the table below:
x y u mean 1 10 100 50.5 2 15 None 2 3 20 400 201.5 - mean_col_name (
-
SUPPORTED_TYPES= ('int', 'float', 'bool', 'string')¶
-
Save(stream_or_filename, format='ost', sep=', ')¶ Save the table to stream or filename. The following three file formats are supported (for more information on file formats, see
Load()):ost ost-specific format (human readable) csv comma separated values (human readable) pickle pickled byte stream (binary) html HTML table context ConTeXt table Parameters: - stream_or_filename (
strorfile) – filename or stream for writing output - format (
str) – output format (i.e. ost, csv, pickle)
Raises: ValueErrorif format is unknown- stream_or_filename (
-
SearchColNames(regex)¶ Returns a list of column names matching the regex.
Parameters: regex ( str) – regex patternReturns: listof column names (str)
-
Select(query)¶ Returns a new table object containing all rows matching a logical query expression.
query is a string containing the logical expression, that will be evaluated for every row.
Operands have to be the name of a column or an expression that can be parsed to float, int, bool or string. Valid operators are: and, or, !=, !, <=, >=, ==, =, <, >, +, -, *, /
subtab = tab.Select('col_a>0.5 and (col_b=5 or col_c=5)')
The selection query should be self explaining. Allowed parenthesis are: (), [], {}, whereas parenthesis mismatches get recognized. Expressions like ‘3<=col_a>=col_b’ throw an error, due to problems in figuring out the evaluation order.
There are two special expressions:
#selects rows, where 1.0<=col_a<=1.5 subtab = tab.Select('col_a=1.0:1.5') #selects rows, where col_a=1 or col_a=2 or col_a=3 subtab = tab.Select('col_a=1,2,3')
Only consistent types can be compared. If col_a is of type string and col_b is of type int, following expression would throw an error: ‘col_a<col_b’
-
SetName(name)¶ Set name of the table
Parameters: name ( str) – name
-
Sort(by, order='+')¶ Performs an in-place sort of the table, based on column by.
Parameters: - by (
str) – column name by which to sort - order (
str(i.e. +, -)) – ascending (-) or descending (+) order
- by (
-
SpearmanCorrel(col1, col2)¶ Calculate the Spearman correlation coefficient between col1 and col2, only taking rows into account where both of the values are not equal to None. If there are not enough data points to calculate a correlation coefficient, None is returned.
Warning: The function depends on the following module: scipy.stats.mstats
Parameters: - col1 (
str) – column name for first column - col2 (
str) – column name for second column
- col1 (
-
Stats(col)¶
-
StdDev(col)¶ Returns the standard deviation of the given column. Cells with ‘’None’’ are ignored. Returns ‘’None’‘, if the column doesn’t contain any elements. Col must be of numeric column type (‘float’, ‘int’) or boolean column type.
Parameters: col ( str) – column nameRaises: TypeErrorif column type isstring
-
Sum(col)¶ Returns the sum of the given column. Cells with ‘’None’’ are ignored. Returns 0.0, if the column doesn’t contain any elements. Col must be of numeric column type (‘float’, ‘int’) or boolean column type.
Parameters: col ( str) – column nameRaises: TypeErrorif column type isstring
-
ToString(float_format='%.3f', int_format='%d', rows=None)¶ Convert the table into a string representation.
The output format can be modified for int and float type columns by specifying a formatting string for the parameters float_format and int_format.
The option rows specify the range of rows to be printed. The parameter must be a type that supports indexing (e.g. a
list) containing the start and end row index, e.g. [start_row_idx, end_row_idx].Parameters: - float_format (
str) – formatting string for float columns - int_format (
str) – formatting string for int columns - rows (iterable containing
ints) – iterable containing start and end row index
- float_format (
-
Zip(*args)¶ Allows to conveniently iterate over a selection of columns, e.g.
tab = Table.Load('...') for col1, col2 in tab.Zip('col1', 'col2'): print col1, col2
is a shortcut for
tab = Table.Load('...') for col1, col2 in zip(tab['col1'], tab['col2']): print col1, col2
-
-
Merge(table1, table2, by, only_matching=False)¶ Returns a new table containing the data from both tables. The rows are combined based on the common values in the column(s) by. The option ‘by’ can be a list of column names. When this is the case, merging is based on multiple columns. For example, the two tables below
x y 1 10 2 15 3 20 x u 1 100 3 200 4 400 when merged by column x, produce the following output:
x y u 1 10 100 2 15 None 3 20 200 4 None 400